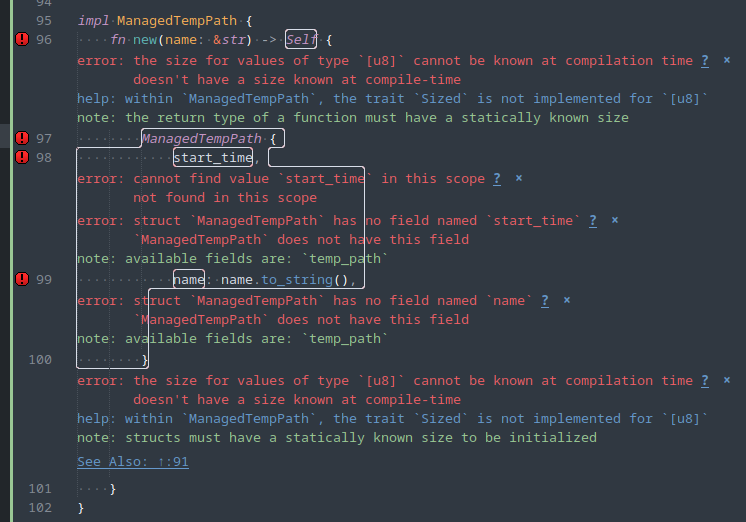
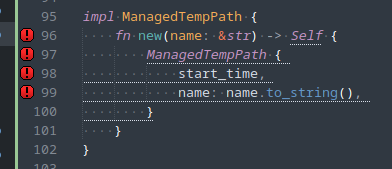
Manjaro has a weird password-quality setup. The password-quality functionality is provided by the libpwquality package, which provides a PAM plugin named pwquality.so and configuration at /etc/security/pwquality.conf . However, once installed it seems to still not be referenced by the PAM configuration and will not be applied to password changes.
Before making changes, open a root prompt. You will make your changes here and have a place to restore your configuration from if you break anything. Make a backup of /etc/pam.d/system-auth .
Make sure you have the libpwquality package installed.
Open /etc/pam.d/system-auth . There are PAM configurations that deal with authenticating the user and PAM configurations that deal with updating passwords. Look for the password-setting configuration block; those lines will have “password” as the module-type (first column):
-password [success=1 default=ignore] pam_systemd_home.so
password required pam_unix.so try_first_pass nullok shadow
password optional pam_permit.so
Insert the line for pam_pwquality.so above (always above) pam_unix.so, and update the configuration for pam_unix.so to:
password requisite pam_pwquality.so retry=3
password required pam_unix.so try_first_pass nullok shadow use_authtok
The change will apply immediately, though you probably will not see a difference with the default password-quality configuration settings.
Make your desired changes to /etc/security/pwquality.conf . We recommend the following settings:
minlen = 10
dcredit = -1
ucredit = -1
lcredit = -1
ocredit = -1
Open the shell for a nonprivileged account that you would like to use to test password changes and proceed to test the password-quality options that you enabled in order to ensure they work as expected. If you made a mistake, fix them in the root console that you should still have open.
Important note: Unless you have enabled “enforce_for_root” in the password-quality or PAM configuration, you will only see advisory warnings for nonconformant passwords when running as root. You will still be able to set any password you’d like.





You must be logged in to post a comment.